Low-Light Enhancement, Denoising, Deblurring and Segmentation
AI-based Image Processing and Computer Vision
![]()

![]()

The human visual system operates using various opponent processes, present in both the retina and visual cortex. These processes heavily rely on distinctions in color, luminance, or motion to trigger salient reactions. Contrast, which refers to differences in luminance and/or color that enable the differentiation of objects, plays a crucial role in subjectively evaluating image quality. Images and videos captured in low-light conditions often exhibit poor quality and visibility due to limitations in shutter angles, high ISO resulting in noise, and spectral biasing toward blue. Traditional enhancement techniques tend to wash out details, flatten the appearance, and amplify noise.
This project aims to develop and validate a perceptually inspired deep learning framework for joint restoration of noisy, low light content (targeting natural history filmmaking) ensuring temporal consistency in terms of colour, luminance and motion.
Methods for Enhancement
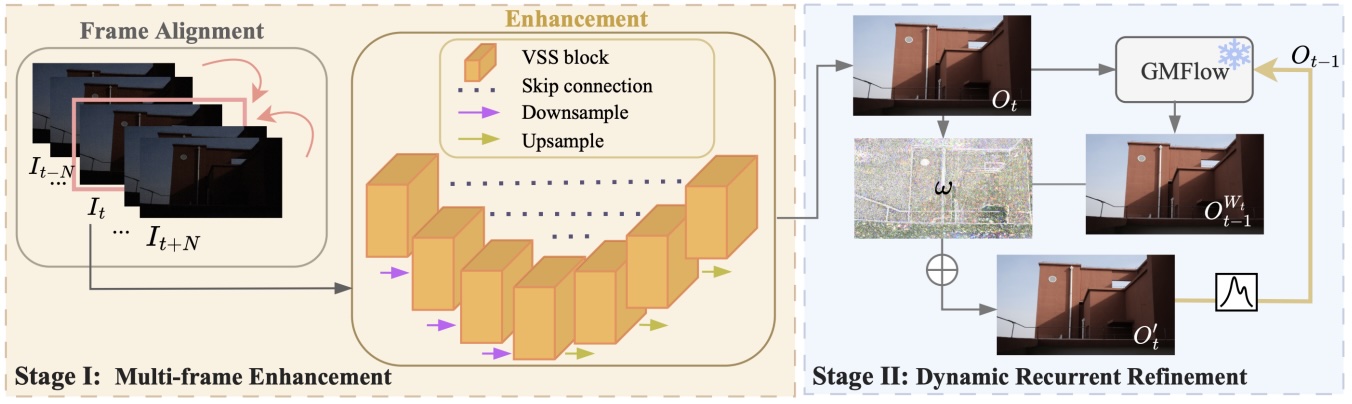
DWTA-Net is a recurrent low-light video enhancement framework designed for extreme noise. Its two-stage design first restores local structure and colour through multi-frame alignment and Mamba-based enhancement, then performs recurrent refinement using a dynamic weight-based temporal aggregation guided by optical flow that adapts to motion. A texture-adaptive loss preserves fine detail in textured regions while suppressing noise in homogeneous areas, yielding stronger noise suppression and fewer artifacts than state-of-the-art methods.
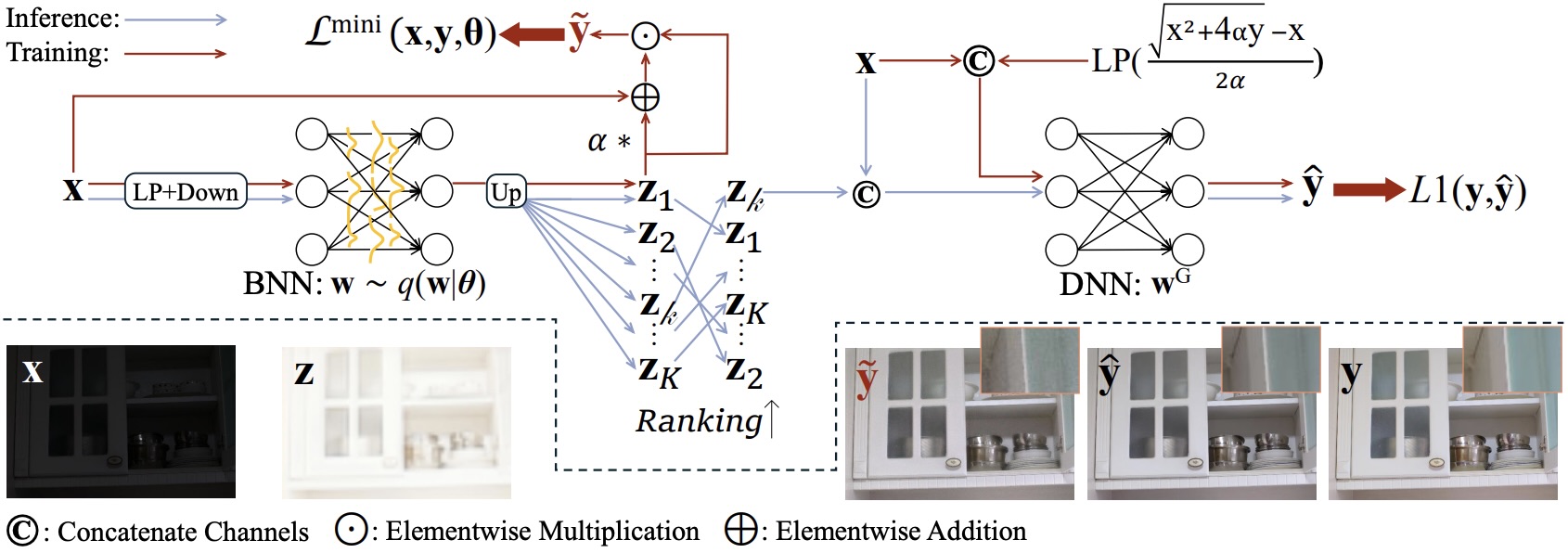
We propose a Bayesian Enhancement Model (BEM) that leverages Bayesian Neural Networks (BNNs) to model data uncertainty and generate diverse outputs. For efficient inference, we adopt a BNN–DNN framework, where a BNN captures the one-to-many mapping in a low-dimensional space, followed by a deterministic network that refines fine-grained details.
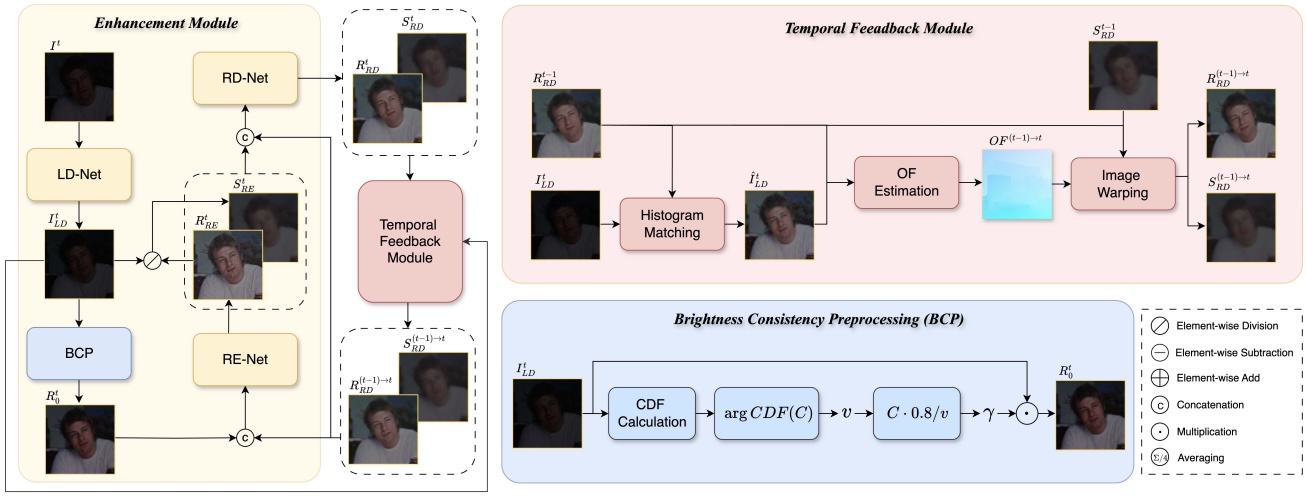
TempRetinex is an unsupervised Retinex-based video enhancement framework that exploits inter-frame correlations. It introduces Brightness Consistency Preprocessing to align intensity across exposures, improving robustness to varied lighting. A multiscale temporal consistency loss with occlusion-aware masking enforces frame coherence, while Reverse Inference and Self-Ensemble further enhance temporal stability and denoising.
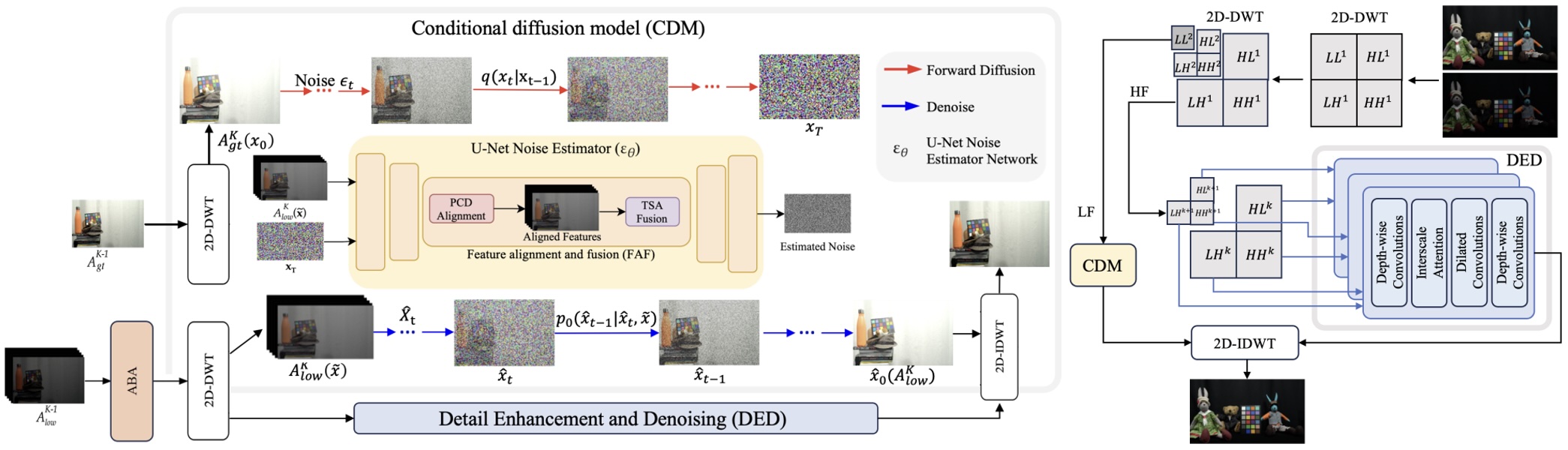
This work introduces a conditional diffusion model for low-light video enhancement equipped with wavelet interscale attentions. By operating in the wavelet domain and conditioning the diffusion process on the degraded input, the method jointly restores illumination and fine detail while suppressing noise and preserving temporal coherence. The approach is released as BVI-CDM.
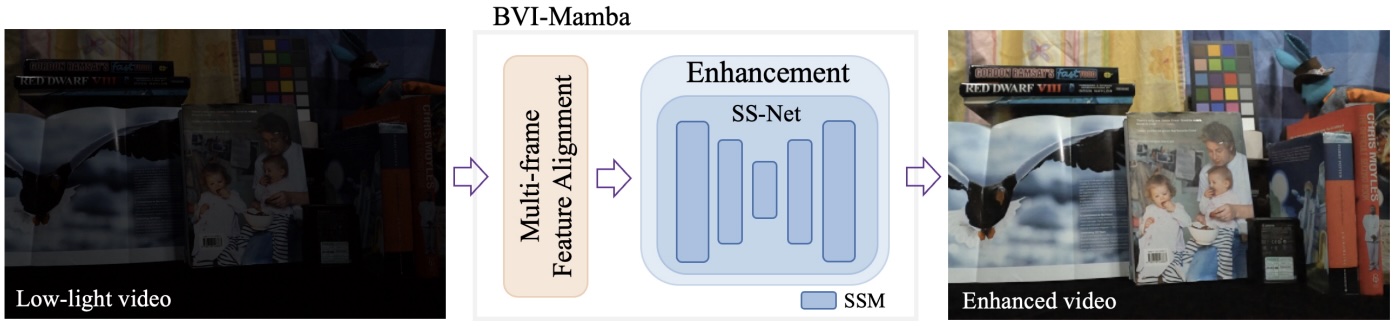
BVI-Mamba is an enhancement framework that leverages the Visual State Space (VSS) model to reduce memory usage and computational time. It comprises a feature alignment module, which registers spatio-temporal displacement between input frames in the feature space, and a UNet-like enhancement module for noise removal and brightness adjustment in which all convolutional layers are replaced by VSS blocks. It outperforms Transformer- and convolution-based models on both low-light and underwater video enhancement.
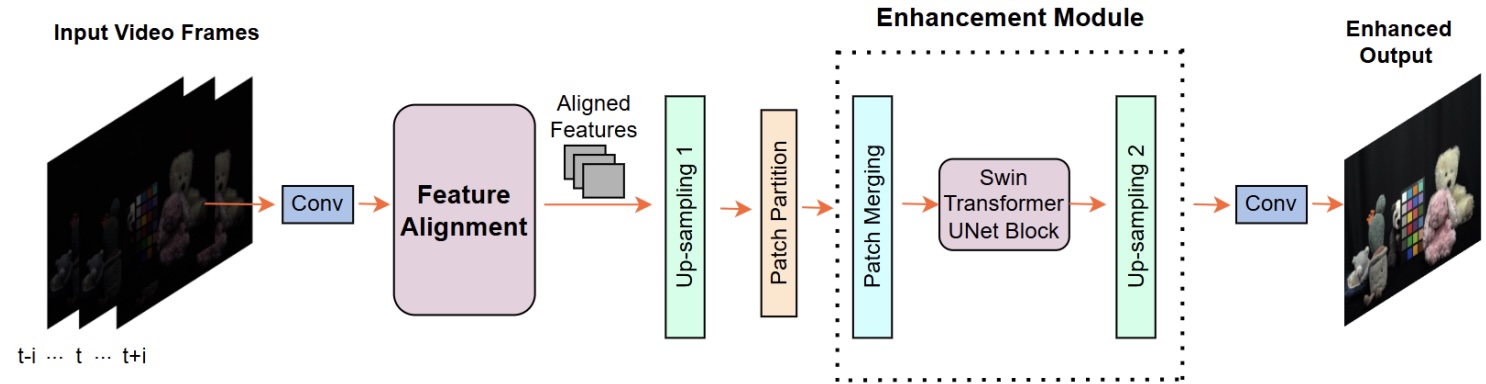
This work introduces a conditional diffusion model for low-light video enhancement equipped with wavelet interscale attentions. By operating in the wavelet domain and conditioning the diffusion process on the degraded input, the method jointly restores illumination and fine detail while suppressing noise and preserving temporal coherence. The approach is released as BVI-CDM.
Methods for Denoising and Deblurring
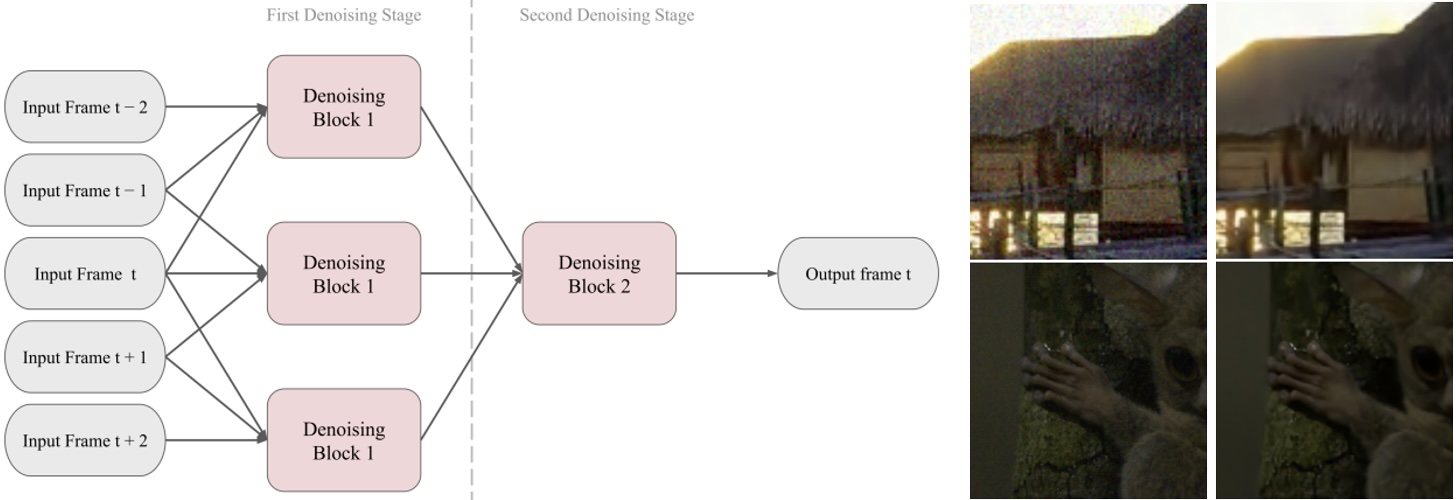
PocketDVDNet is a lightweight, real-time video denoiser built with a model-compression framework that combines sparsity-guided structured pruning, a physics-informed noise model, and knowledge distillation. Starting from a reference model, sparsity is induced and channels are pruned, then a teacher is retrained on realistic multi-component sensor noise so the student learns implicit noise handling without explicit noise-map inputs. It reduces model size by 74% while improving denoising quality and processing 5-frame patches in real time.
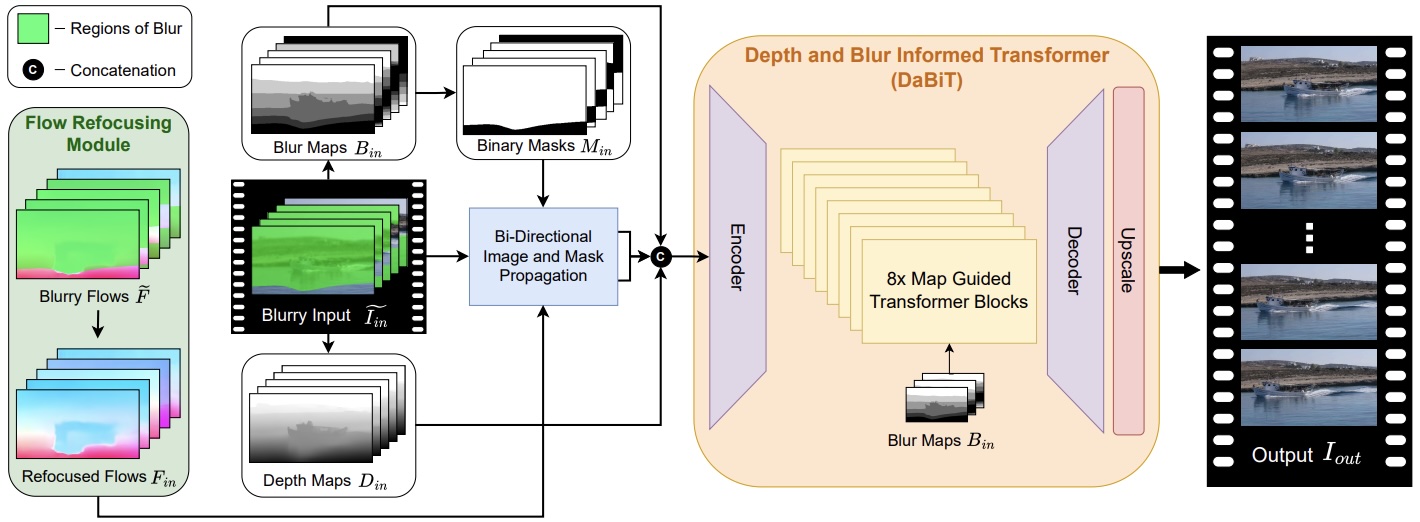
DaBiT presents a novel map-guided transformer that, together with image propagation, effectively leverages the continuous spatial variation of focal blur to restore degraded footage. We also introduce a flow re-focusing module designed to efficiently align relevant features between blurry and sharp domains. In addition, we propose a novel synthetic focal blur data generation technique, which broadens the model’s learning capabilities and improves its robustness across a wider range of content.
Methods for Segmentation and Detection
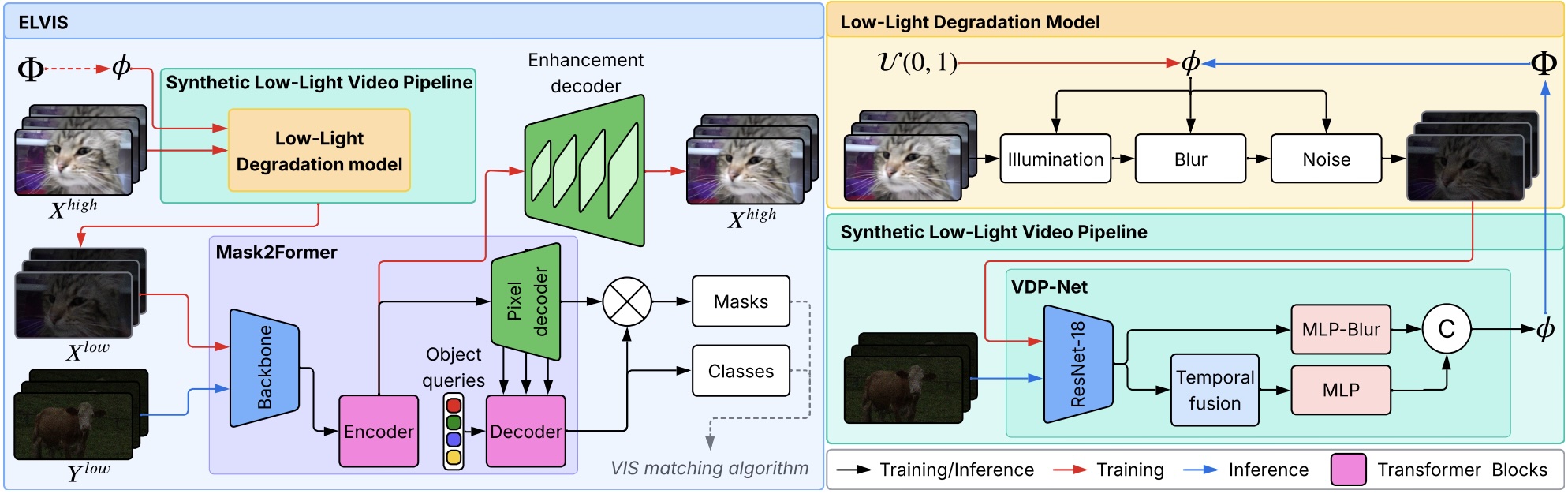
ELVIS enables domain adaptation of state-of-the-art video instance segmentation (VIS) models to low-light scenarios. It comprises an unsupervised synthetic low-light video pipeline that models both spatial and temporal degradations, a calibration-free degradation profile estimation network (VDP-Net), and an enhancement decoder head that disentangles degradations from content features. ELVIS improves performance by up to +3.7 AP on the synthetic dataset and beats two-stage baselines by at least +2.8 AP on real low-light videos.
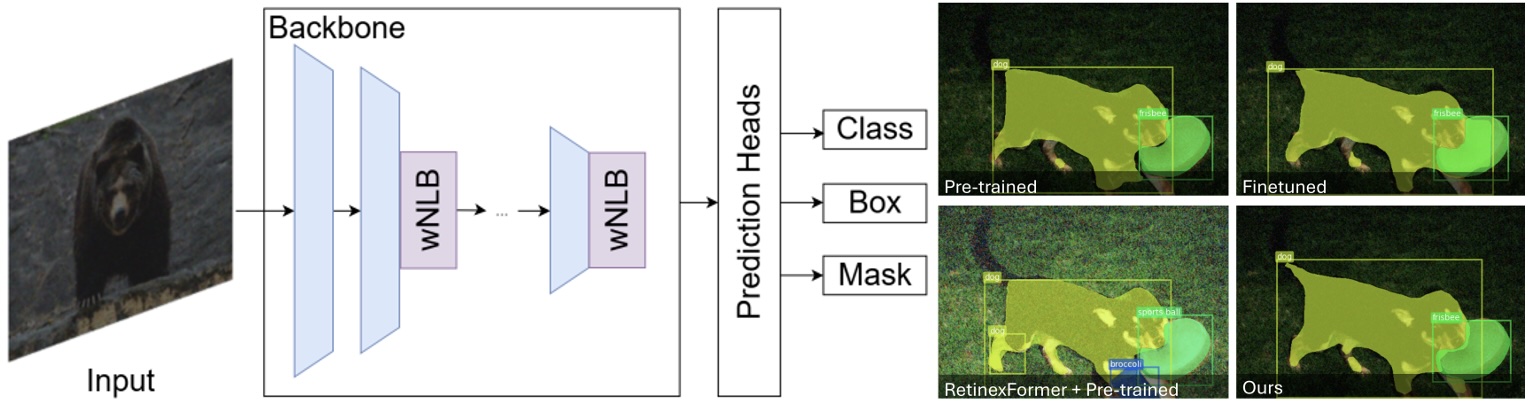
This method performs instance segmentation directly on low-light imagery by embedding weighted non-local blocks (wNLB) in the feature extractor, enabling an inherent denoising process at the feature level. Because denoising happens in feature space, the approach removes the need for aligned ground-truth images and can be trained on real-world low-light data. Additional learnable per-layer weights adapt the network to real noise characteristics across feature scales, improving AP by at least +7.6 over pretrained detectors.
This paper presents a comprehensive study examining the impact of these distortions on automatic object trackers. Additionally, we propose a solution to enhance the tracking performance by integrating denoising and low-light enhancement methods into the transformer-based object tracking system.
Methods for Data Simulators
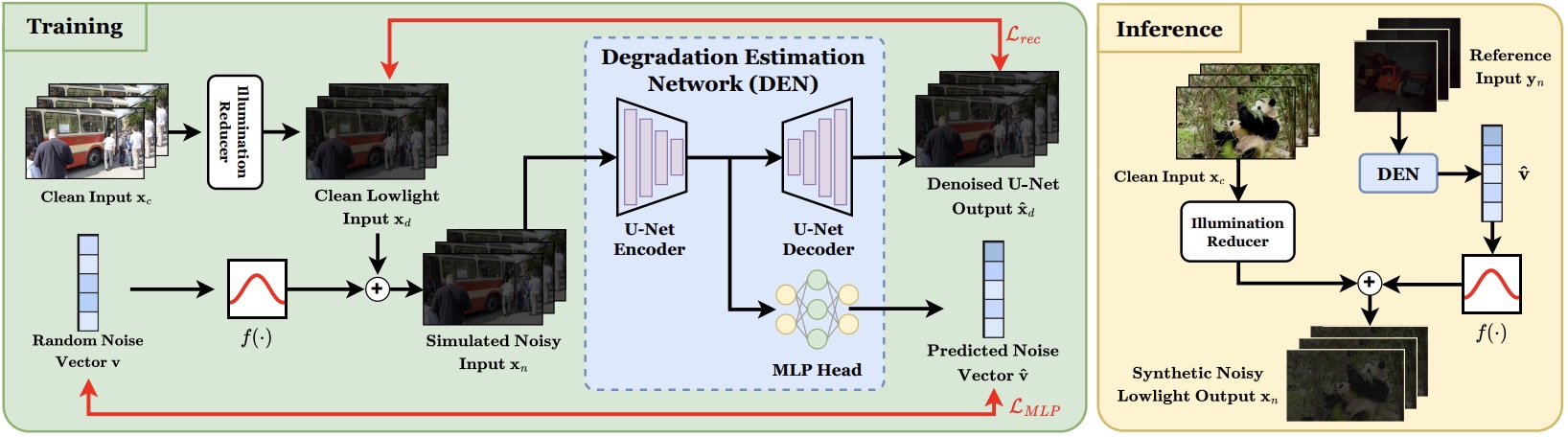
This work proposes a Degradation Estimation Network (DEN) that synthetically generates realistic standard RGB (sRGB) noise without requiring camera metadata, by estimating the parameters of physics-informed noise distributions in a self-supervised manner. This zero-shot pipeline produces synthetic noisy content with a diverse range of realistic noise characteristics, rather than merely replicating a single training distribution. Evaluated across synthetic noise replication, video enhancement, and object detection, it delivers improvements of up to 24% KLD, 21% LPIPS, and 62% AP.
Research team
Core
- N. Anantrasirichai and D.R. Bull: Lead academics
- Guoxi Huang (Edward): Researcher on low-light enhancement [BVI-Mamba] [BEM Paper, CODE]
- Crispian Morris: PhD on low-ight autofocus for advanced wildlife coverage (with BBC R&D) [DaBiT Paper] [PocketDVDNet Paper]
- Rachel Lin: PhD on super low-light video enhancement [Paper1, Code] [Paper2, Code] [arXiv, Dataset]
- Joanne Lin: PhD on segmentation and object tracking in low-light environment [Paper1, Code] [Paper2, Code] [ELVIS Paper, Project]
- Yini Li: PhD on unsupervised low-light video enhancement [Paper, Code]
Alumni
- Alexandra Malyugina: Researcher on low-light image denoising [Project page] [Paper1] [Paper2]
- Duolikun Danier: Researcher on low-light image enhancement
Undergrad/Postgrad projects
- Qi (Karlee) Sun (2024), Low-light video enhancement with conditional diffusion model [Thesis] [Paper, Code]
- Anastasia Yi (2023), A comprehensive study of object tracking in low-light environments [Thesis] [Paper]
- Siyu Zhou (2023), Temporal consistency in low-light video enhancement [Thesis]
- Felicia Dubicki-Piper (2023), VideoINR+: Video denoising with implicit neural representation [Code]
Downloads
Publications
- ELVIS: Enhance Low-light for Video Instance Segmentation in the Dark. J Lin, R Lin, Y Li, D Bull, N Anantrasirichai, IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2026
[ PDF] [Project] - Bayesian Neural Networks for One-to-Many Mapping in Image Enhancement. G Huang, Z Qi, RR Lin, Q Yang, D Bull, N Anantrasirichai, AAAI Conference on Artificial Intelligence. 2026 [PDF] [CODE]
- PocketDVDNet: Realtime Video Denoising for Real Camera Noise. C Morris, I Dexter, F Zhang, DR Bull, N Anantrasirichai. IEEE International Conference on Acoustics, Speech, and Signal Processing. 2026 [PDF]
- Zero-TIG: Temporal Consistency-Aware Zero-Shot Illumination-Guided Low-light Video Enhancement. Y Li, N Anantrasirichai, 33rd European Signal Processing Conference [PDF] [Code]
- Towards a General-Purpose Zero-Shot Synthetic Low-Light Image and Video Pipeline. J Lin, C Morris, R Lin, F Zhang, D Bull, N Anantrasirichai, ACM International Conference on Multimedia Workshop. 2025
[ PDF] [ CODE] - BVI-Mamba: video enhancement using a visual state-space model for low-light and underwater environments. G Huang, R Lin, Y Li, D Bull, N Anantrasirichai, Machine Learning from Challenging Data [PDF] [Code]
- Feature Denoising For Low-Light Instance Segmentation Using Weighted Non-Local Blocks. J Lin, N Anantrasirichai, D Bull, IEEE International Conference on Acoustics, Speech, and Signal Processing. 2025
[ PDF] [Code] - Wavelet-Based Topological Loss for Low-Light Image Denoising. A Malyugina, N Anantrasirichai, D Bull, Sensors. 2025
[ PDF] - Low-light Video Enhancement with Conditional Diffusion Models and Wavelet Interscale Attentions. R Lin, Q Sun, N Anantrasirichai. ACM SIGGRAPH Conference on Visual Media Production. 2024
[ PDF] - A comprehensive study of object tracking in low-light environments. A Yi and N Anantrasirichai. Sensors. 2024
[ PDF] - A Spatio-temporal Aligned SUNet Model for Low-light Video Enhancement. R Lin, N Anantrasirichai, A Malyugina, D Bull. IEEE International Conference on Image Processing. 2024
[ PDF] [ CODE] [ Dataset] - Topological Loss Function for Image Denoising on a new BVI-lowlight Dataset. A. Malyugina, N. Anantrasirichai, and D. Bull. Signal Processing. 2023. [PDF]
- Contextual colorization and denoising for low-light ultra high resolution sequences. N. Anantrasirichai and D. Bull. In Proceedings of the IEEE International Conference on Image Processing. 2021 [PDF] [Project page]
Datasets
- Paired video dataset for low-light enhancement [dataset] [arXiv]
- Paired image dataset for image denoising [dataset] [paper]
- Unpaired UHD video dataset [dataset] [paper]
Code
- BEM [https://github.com/BinCVER/BEM]
- BVI-Mamba [https://github.com/russellllaputa/BVI-Mamba]
- BVI-CDM [https://github.com/lrr-rachel/BVI-CDM]
- STA-SUNet [https://github.com/lrr-rachel/STA-SUNet]
- PCDUNet [https://github.com/lrr-rachel/PCDUNet]
Related research
Related publications from VI-Lab
- Artificial intelligence in the creative industries: A review. N Anantrasirichai and D R Bull, Artif Intell Rev 55, 2022
- ST-MFNet Mini: Knowledge distillation-driven frame interpolation. C Morris, D Danier, F Zhang, N Anantrasirichai, D R Bull. IEEE International Conference on Image Processing. 2023